WARNING (pytensor.tensor.blas): Using NumPy C-API based implementation for BLAS functions.4 MCMC Diagnostics
The Achilles heel of computing posterior distributions is, more often than not, the computation of the denominator of Bayes’s theorem. Markov Chain Monte Carlo Methods (MCMC), such as Metropolis, Hamiltonian Monte Carlo (and its variants like NUTS) are clever mathematical and computational devices that let us circumvent this problem. The main idea is based on sampling values of the parameters of interest from an easy-to-sample distribution and then applying a rule, known as the Metropolis acceptance criterion, to decide if you accept or not that proposal. By applying this rule we ensure that even when we propose samples from an arbitrary distribution we end up getting samples from the correct posterior distribution. The better performance of NUTS over Metropolis can be explained by the fact that the former uses a clever way to propose values.
While MCMC methods can be successfully used to solve a huge variety of Bayesian models, they have some trade-offs. Most notably, finite MCMC chains are not guaranteed to converge to the true posterior distribution. Thus, a key step is to check whether we have a valid sample, otherwise, any analysis from it will be totally flawed.
There are several tests we can perform, some are visual and some are numerical. These tests are designed to spot problems with our samples, but they are unable to prove we have the correct distribution; they can only provide evidence that the sample seems reasonable.
In this chapter, we will cover the following topics:
- Trace plots
- Rank plots
- \(\hat R\)
- Effective Sample Size
- Divergences
4.1 From the MCMC theory to practical diagnostics
The theory describes certain behaviors of MCMCs methods, many diagnoses are based on evaluating whether the theoretical results are empirically verified. For example, MCMC theory says that:
- The initial value is irrelevant, we must always arrive at the same result
- The samples are not really independent, but the value of a point only depends on the previous point, there are no long-range correlations.
- If we look at the sample as a sequence we should not be able to find any patterns.
- For example, for a sufficiently long sample, the first portion must be indistinguishable from the last (and so should any other combination of regions).
- For the same problem, each sample generated will be different from the others, but for practical purposes, the samples should be indistinguishable from each other.
We are going to see that many diagnostics need multiple chains. Each chain is an independent MCMC run. The logic is that by comparing independent runs we can more easily sport issues than running a single instance. This multiple-chain approach also takes advantage of modern hardware. If you have a CPU with 4 cores you can get 4 independent chains in essentially the same time that one single chain.
To keep the focus on the diagnostics and not on any particular Bayesian model. We are going to first create 3 synthetic samples, we will use them to emulate samples from a posterior distribution.
good_sample: A random sample from aGamma(2, 5). This is an example of a good sample because we are generating independent and identically distributed (iid) draws. This is the ideal scenario.bad_sample_0: We sorted good_sample, split it into two chains, and then added a small Gaussian error. This is a representation of a bad sample because values are not independent (we sorted the values!) and they do not come from the same distribution, because of the split the first half has values that are lower than the second. This represents a scenario where the sampler has very poor mixing.bad_sample_1: we start fromgood_chains, and turn into a poor sample by randomly introducing portions where consecutive samples are highly correlated to each other. This represents a common scenario, a sampler can resolve a region of the parameter space very well, but get stuck into one or more regions.
Show the code for more details
good_sample = pz.Gamma(2, 5).rvs((2, 2000))
bad_sample0 = np.random.normal(np.sort(good_sample, axis=None), 0.05,
size=4000).reshape(2, -1)
bad_sample1 = good_sample.copy()
for i in np.random.randint(1900, size=4):
bad_sample1[i%2:,i:i+100] = pz.Beta(i, 150).rvs(size=100)
sample = {"good_sample":good_sample,
"bad_sample_0":bad_sample0,
"bad_sample_1":bad_sample1}
Note
After reading this chapter a good exercise is to come back here and modify these synthetic samples and run one or more diagnostics. If you want to make the exercise even more fun challenge yourself to predict what the diagnostics will be before running, or the other way around how you should change the samples to get a given result. This is a good test of your understanding and a good way to correct possible misunderstandings.
4.2 Trace plots
A trace plot is created by drawing the sampled values at each iteration step. Ideally, we should expect to see a very noisy plot, some people call it a caterpillar. The reason is that draws should be uncorrelated from each other, the value of a draw should not provide any hint about the previous or next draw. Also, the draws from the first iterations should be indistinguishable from the ones coming from the last iterations the middle iterations, or any other region. The ideal scenario is the lack of any clear pattern as we can see at the right panel of Figure 4.1.
In ArviZ by calling the function az.plot_trace(.) we get a trace plot on the right and on the left a KDE (for continuous variables) or a histogram (for discrete variables). Figure 4.1 is an example of this. The KDE/histogram can help to spot differences between chains, ideally, distributions should overlap.

This represents a scenario where the sampler is visiting two different regions of the parameter space and is not able to jump from one to the other. Additionally, it is also moving very slowly within each region. Figure 4.2 shows two problems. On the one hand, each chain is visiting a different region of the parameter space. We can see this from the trace plot itself and the KDE. On the other hand, even within each region, the sampler is having trouble properly exploring the space, notice how it keeps moving up, instead of being stationary.

Finally from Figure 4.3, we can see another common scenario. This time we see that globally everything looks fine. But there are 3 regions where the sampler gets stuck, see the orange lines at the bottom of the traceplot. For the first two regions, starting at iterations 736 and 916, both chains got stuck. For the third region, starting in 1463, only one chain got stuck.
Code

Trace plots are probably the first plots we make after inference and also probably the most popular plots in Bayesian literature. But there are more as we will see next.
4.3 Rank plots
The basic idea is the following. For a parameter we take all the chains and order the values from lowest to highest and assign them a rank, that is, to the lowest value assign 0, to the following 1, and so on until we reach the total number of samples, (number of chains multiplied by the number of draws per chain). Then we regroup the rankings according to the chains that gave rise to them and for each chain we make a histogram. If the chains were indistinguishable we would expect the histograms to be uniform. Since there is no reason for one chain to have more low (or medium or high) rankings than the rest.
Figure 4.4 shows rank plots for good_sample, bad_sample_0 and bad_sample_1. Notice how good_sample looks pretty close to uniform, bad_sample_1 is harder to tell, because overall it looks very close to uniform, except for the penultimate bar. On the contrary bad_sample_0 really looks bad.
4.4 \(\hat R\) (R-hat)
Plots are often useful for discovering patterns, but sometimes we want numbers, for example when quickly evaluating many parameters it may be easier to look at numbers than plots. Number are also easier to plug into some automatic routine, that call for human attention only if some threshold is exceeded.
\(\hat R\) is a numerical diagnostic that answers the question. Did the chains mix properly? But I also like to think of it as the score assigned by a jury in a trace (or rank) plot contest.
The version implemented in ArviZ does several things under the hood, but the central idea is that it compares the variance between chains with the variance within each chain. Ideally, we should get \(\hat R = 1\), in practice \(\hat R \lessapprox 1.01\) are considered safe and in the first modeling phases, even higher values like \(\hat R \approx 1.1\) may be fine.
Using ArviZ we can get the \(\hat R\) usando az.rhat(⋅), az.summary(⋅) and az.plot_forest(⋅, r_hat=True)
<xarray.Dataset> Size: 24B
Dimensions: ()
Data variables:
bad_sample_0 float64 8B 2.667
bad_sample_1 float64 8B 1.006
good_sample float64 8B 1.04.4.1 Effective Sample Size (ESS)
Since the samples of an MCMC are (auto)correlated, the amount of “useful” information is less than a sample of the same size but iid. Figure 4.5 can help us develop intuition. In this figure, we analyze the error incurred while computing an estimate (such as the mean) from samples of different size, considering varying degrees of autocorrelation. The results represent averages from 1000 repetitions.
We can see that the error goes down as the sample size increases and we can also see that the lower the autocorrelation the smaller the sample size to achieve an estimate with a given error. In other words the higher the autocorrelation the larger the number of sample we will need to achieve the a given precision.
Show the code for more details
def generate_autocorrelated_sample(original, rho):
"""
Generates an autocorrelated sample from original.
Parameters:
----------
sample: numpy array,
The original sample
rho: float,
Desired autocorrelation value
Returns:
--------
new_sample: numpy array, autocorrelated sample
"""
n = len(original)
y = np.copy(original)
mean = np.mean(original)
for i in range(1, n):
y[i] += rho * (y[i-1]-mean) + np.random.randn()
return y
mean = 0
lag = 30
size = 300
iid_samples = np.random.normal(mean, 1, size=(1000, size))
rhos = np.linspace(0, 0.90, 7)
N = len(rhos)
fig, ax = plt.subplots()
for k, rho in enumerate(rhos):
auto_samples = np.stack([generate_autocorrelated_sample(iid_sample, rho) for iid_sample in iid_samples])
auto_error = []
for i in range(1, size):
auto_error.append(np.mean(((np.mean(auto_samples[:,:i] - mean, 1)**2)**0.5)))
ax.plot(auto_error[lag:], color=plt.cm.viridis_r(k/N))
sm = plt.cm.ScalarMappable(cmap=plt.cm.viridis_r)
cbar = plt.colorbar(sm, ax=ax, label='Autocorrelation', ticks=[0, 1])
cbar.ax.set_yticklabels(['Low', 'High'])
cbar.ax.tick_params(length=0)
ax.set_yticks([])
ax.set_ylabel("Error")
ax.set_xticks([])
ax.set_xlabel("Sample size")
ax.set_ylim(bottom=0)
ax.set_xlim(-2)
ax.spines["top"].set_visible(False)
ax.spines["right"].set_visible(False)
ax.plot(1, 0, ">k", transform=ax.get_yaxis_transform(), clip_on=False)
ax.plot(-2, 1, "^k", transform=ax.get_xaxis_transform(), clip_on=False)
As for MCMC samples, the sample size can be misleading, we instead estimate the effective sample size (ESS), that is, the size of a sample with the equivalent amount of information but without autocorrelation. Figure 4.6 shows how when the sample size increases the ESS tends to increase too, and more importantly, it shows that the slope is higher for lower autocorrelation values.
Show the code for more details
mean = 0
size = 300
iid_samples = np.random.normal(mean, 1, size=(500, size))
rhos = np.linspace(0, 0.90, 7)
N = len(rhos)
fig, ax = plt.subplots()
for k, rho in enumerate(rhos):
auto_samples = np.stack([generate_autocorrelated_sample(iid_sample, rho) for iid_sample in iid_samples])
auto_error = []
for i in range(50, size, 10):
auto_error.append(az.stats.ess(auto_samples[:,:i])/500)
ax.plot(range(50, size, 10), auto_error, color=plt.cm.viridis_r(k/N))
sm = plt.cm.ScalarMappable(cmap=plt.cm.viridis_r)
cbar = plt.colorbar(sm, ax=ax, label='Autocorrelation', ticks=[0, 1])
cbar.ax.set_yticklabels(['Low', 'High'])
cbar.ax.tick_params(length=0)
ax.set_yticks([])
ax.set_ylabel("Effective sample size")
ax.set_xticks([])
ax.set_xlabel("Sample size")
ax.set_ylim(0)
ax.set_xlim(48)
ax.spines["top"].set_visible(False)
ax.spines["right"].set_visible(False)
ax.plot(1, 0, ">k", transform=ax.get_yaxis_transform(), clip_on=False)
ax.plot(48, 1, "^k", transform=ax.get_xaxis_transform(), clip_on=False)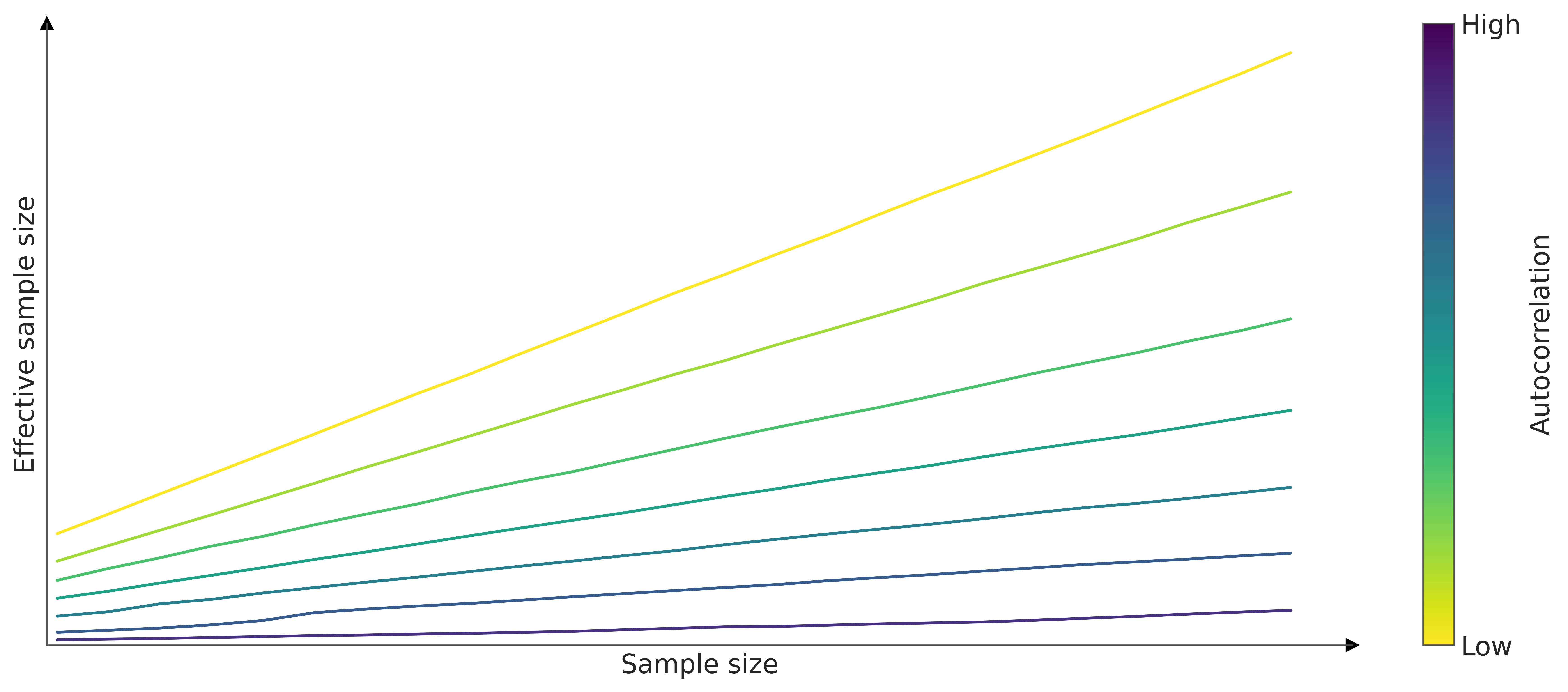
With ArviZ we can get az.ess(⋅), az.summary(⋅) and az.plot_forest(⋅, ess=True)
<xarray.Dataset> Size: 24B
Dimensions: ()
Data variables:
bad_sample_0 float64 8B 2.344
bad_sample_1 float64 8B 272.7
good_sample float64 8B 3.988e+03One way to use the ESS is as a minimum requirement for trustworthy MCMC samples. It is recommended the ESS to be greater than 100 per chain. That is, for 4 chains we want a minimum of 400 effective samples.
Note
The ESS can also be used as a metric of the efficiency of MCMC sampling methods. For instance, we may want to measure the ESS per sample (ESS/n), a sampler that generates a ESS/n closer to 1 is more efficient than a sampler that generates values closer to 0. Other common metrics are the ESS per second, and the ESS per likelihood evaluation.
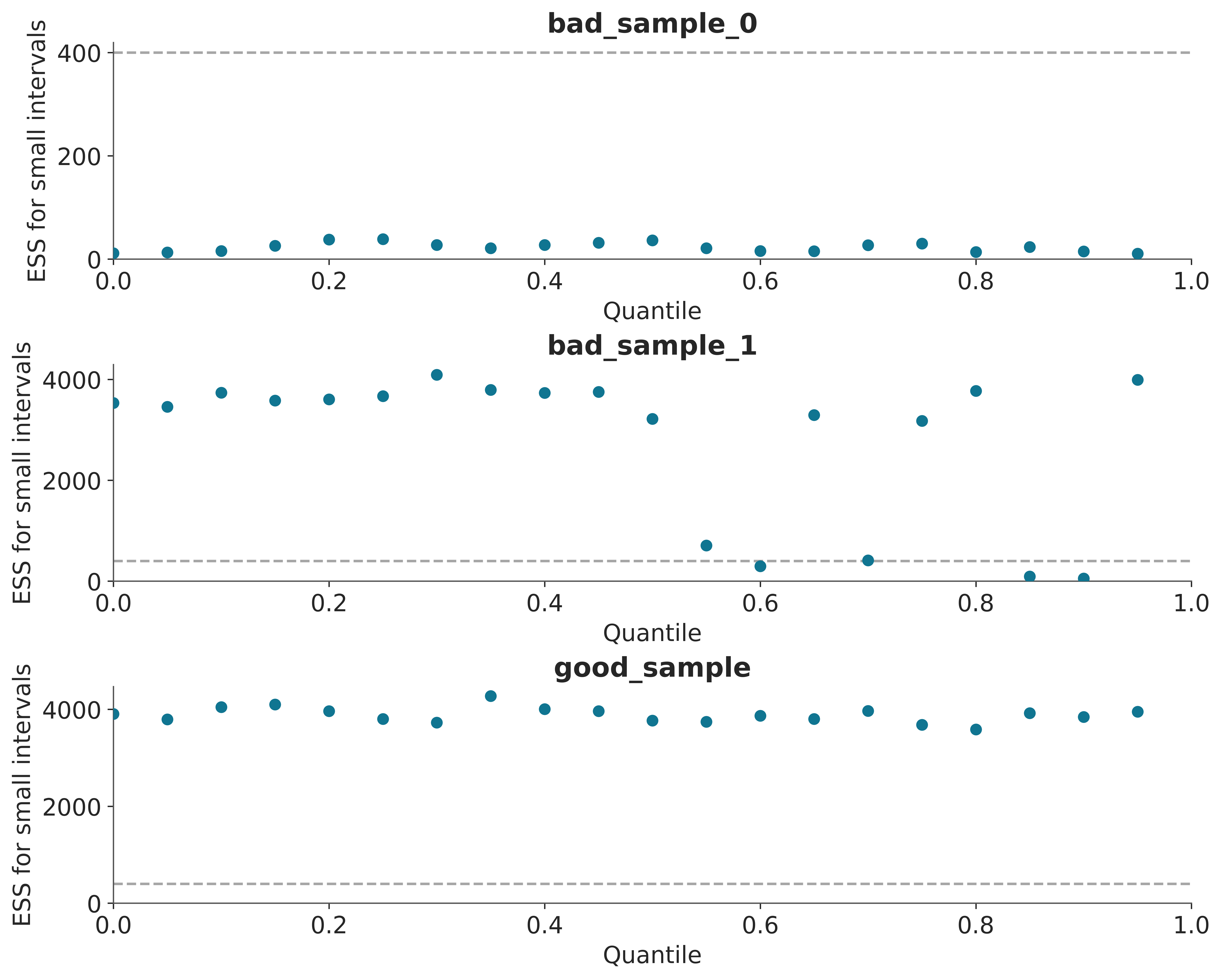
We see that az.summary(⋅) returns two ESS values, ess_bulk and ess_tail. This is because different regions of the parameter space may have different ESS values since not all regions are sampled with the same efficiency. Intuitively, one may think that when sampling a distribution like a Gaussian it is easier to obtain better sample quality around the mean than around the tails, simply because we have more samples from that region. For some models, it could be the other way around, but the take-home message remains, not all regions are necessarily sampled with the same efficiency
| mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|
| bad_sample_0 | 0.181 | 0.147 | 2.0 | 11.0 | 2.67 |
| bad_sample_1 | 0.020 | 0.014 | 273.0 | 3482.0 | 1.01 |
| good_sample | 0.004 | 0.003 | 3988.0 | 4008.0 | 1.00 |
If we are going to use the MCMC samples to calculate central values such as means or medians then we have to make sure that the ess_bulk is sufficiently large, however, if we want to calculate intervals such as an HDI 94% we have to make sure that ess_tail be appropriate.
ArviZ offers several functions linked to the ESS. For example, if we want to evaluate the performance of the sampler for several regions at the same time we can use az.plot_ess.
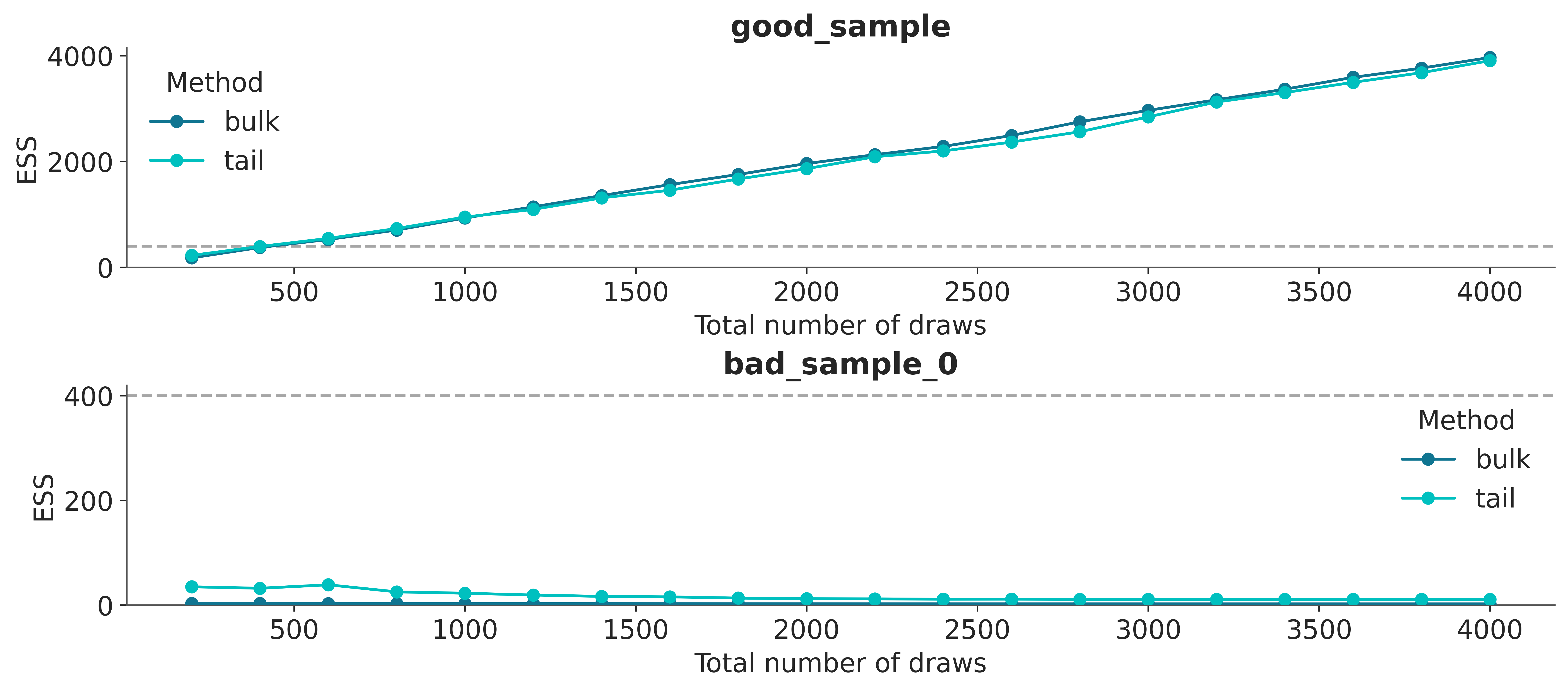
A simple way to increase the ESS is to increase the number of samples, but it could be the case that the ESS grows very slowly with the number of samples, so even if we increased the number of samples 10 times we could still be very far from our target value. One way to estimate “how many more samples do we need” is to use az.plot_ess(⋅, kind="evolution"). This graph shows us how the ESS changed with each iteration, which allows us to make predictions.
From Figure 4.7 we can see that the ESS grows linearly with the number of samples for good_sample, and it does not grow at all for bad_sample_0. In the latter case, this is an indication that there is virtually no hope of improving the ESS simply by increasing the number of draws.
4.4.2 Monte Carlo standard error (MCSE)
An advantage of the ESS is that it is scale-free, it does not matter if one parameter varies between 0.1 and 0.2 and another between -2000 and 0, an ESS of 400 has the same meaning for both parameters. In models with many parameters, we can quickly identify which parameters are most problematic. However, when reporting results it is not very informative to know whether the ESS was 1372 or 1501. Instead, we would like to know the order of the errors we are making when approximating the posterior. This information is given by the Monte Carlo standard error (MCSE). Like the ESS, the MCSE takes into account the autocorrelation of the samples. This error should be below the desired precision in our results. That is, if for a parameter the MCSE is 0.1, it does not make sense to report that the mean of that parameter is 3.15. Since the correct value could easily be between 3.4 and 2.8.
With ArviZ we can get the MCSE with az.mcse(⋅) or az.summary(⋅).
4.4.3 Thinning
One way to reduce autocorrelation in an MCMC chain is through thinning, where we retain only every \(n\)-th sample. While this method is straightforward, it has the drawback of discarding useful information. Research generally suggests that it’s better to keep all the samples when calculating estimates (MacEachern and Berliner 1994; Link and Eaton 2012). Provided the variance is finite, the central limit theorem applies even to correlated samples. Then if higher accuracy is needed, it’s more effective to increase the number of draws rather than to perform thinning. Still, there are situations where thinning might be useful, such as:
- Reducing the size of stored data, which is especially important when dealing with a large number of models or when the postprocessing of the samples is expensive, for instance when we need to run expensive computations on every draw.
- Addressing bias in extreme ordered statistics, which may affect diagnostics like rank-plots (Section 4.3) and uniformity tests typically done for posterior predictive checks, as shown in Figure 5.7 and Figure 6.2 or as part of Simulation Based Calibration (Talts et al. 2020).
To determine an appropriate thinning factor, we can use the effective sample size (ESS). For instance, if you have 2,000 samples and an ESS of 1,000, you would thin by a factor of 2, keeping every other sample. The higher the ESS, the lower the thinning factor required. A more refined approach is to calculate both ESS-tail and ESS-bulk, then use the smaller value, which better accounts for differences in sampling efficiency between the central 90% quantile and the 5% tail quantiles (Säilynoja, Bürkner, and Vehtari 2022).
In ArviZ we have the thin function, which allows us to perform thinning automatically.
Additionally, if needed, we can specify the thinning factor manually or we can pass a target_ess, this last option is useful when we want as much thinning as possible provided we still get an ESS around the specified value of target_ess.
4.5 Diagnosis of gradient-based algorithms
Due to its internal workings, algorithms like NUTS offer some specific tests that are not available to other methods. These tests are generally very sensitive.
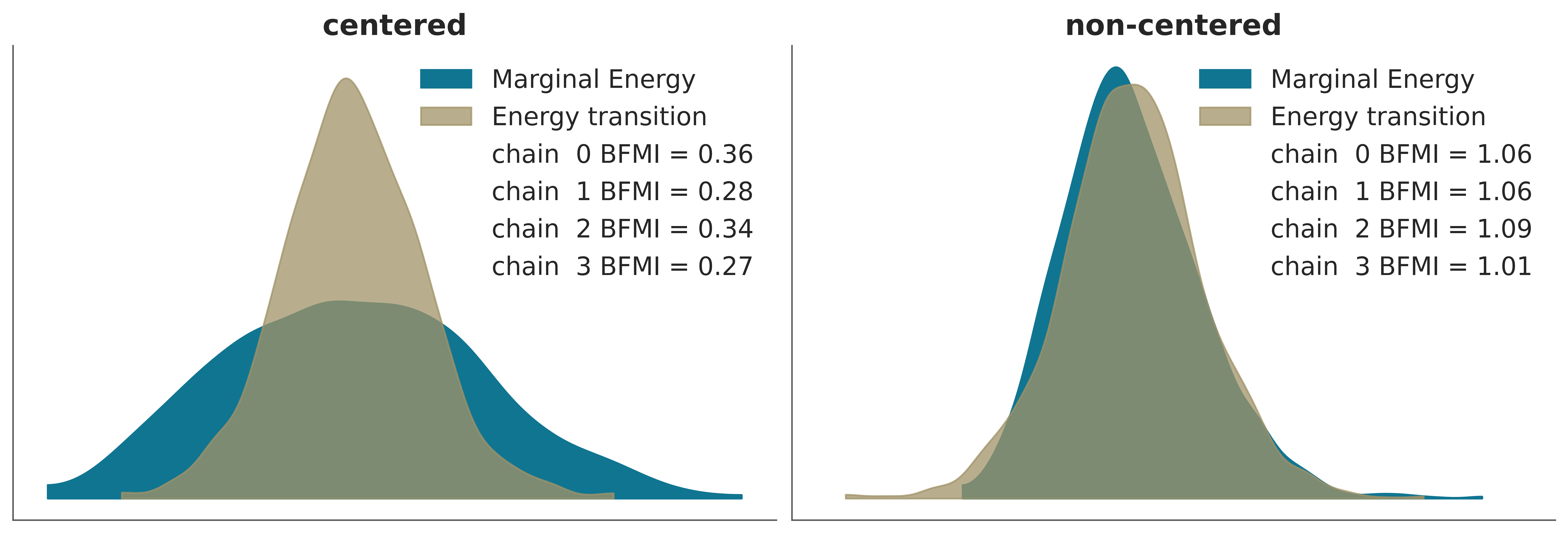
To exemplify this we are going to load two InferenceData from pre-calculated models. The details of how these data were generated are not relevant at the moment. We will only say that they are two models that are mathematically equivalent but parameterized in different ways. In this case, the parameterization affects the efficiency of the sampler. The centered model is sampled more efficiently than the uncentered model.
4.5.1 Transition energy vs marginal energy
We can think of a Hamiltonian Monte Carlo as a two-step process
- Deterministic sampling (following the Hamiltonian)
- A random walk in momentum space
If the transition energy distribution is similar to the marginal energy distribution, then NUTS can generate samples of the marginal energy distribution that are almost independent between transitions. We can evaluate this visually or numerically, calculating the Bayesian Fraction of Missing Information (BFMI), as shown in the following figure.
4.5.2 Divergences
One advantage of NUTS is that it fails with style. This happens, for example, when trying to go from regions of low curvature to regions of high curvature. In these cases, the numerical trajectories may diverge. Essentially this happens because in these cases there is no single set of hyper-parameters that allows efficient sampling of both regions. So one region is sampled properly and when the sampler moves to the other region it fails. Divergent numerical trajectories are extremely sensitive identifiers of pathological neighborhoods.
The following example shows two things the non-centered model shows several divergences (turquoise circles) grouped in one region. In the centered model, which has no divergence, you can see that around that same region, there are samples for smaller values of tau. That is to say, the ‘uncentered’ model fails to sample a region, but at least it warns that it is having problems sampling that region!
_, axes = plt.subplots(1, 2, sharey=True, sharex=True, figsize=(10, 5), constrained_layout=True)
for ax, idata, nombre in zip(axes.ravel(), (idata_cm, idata_ncm), ("centered", "non-centered")):
az.plot_pair(idata, var_names=['theta', 'tau'], coords={'school':"Choate"}, kind='scatter',
divergences=True, divergences_kwargs={'color':'C1'},
ax=ax)
ax.set_title(nombre)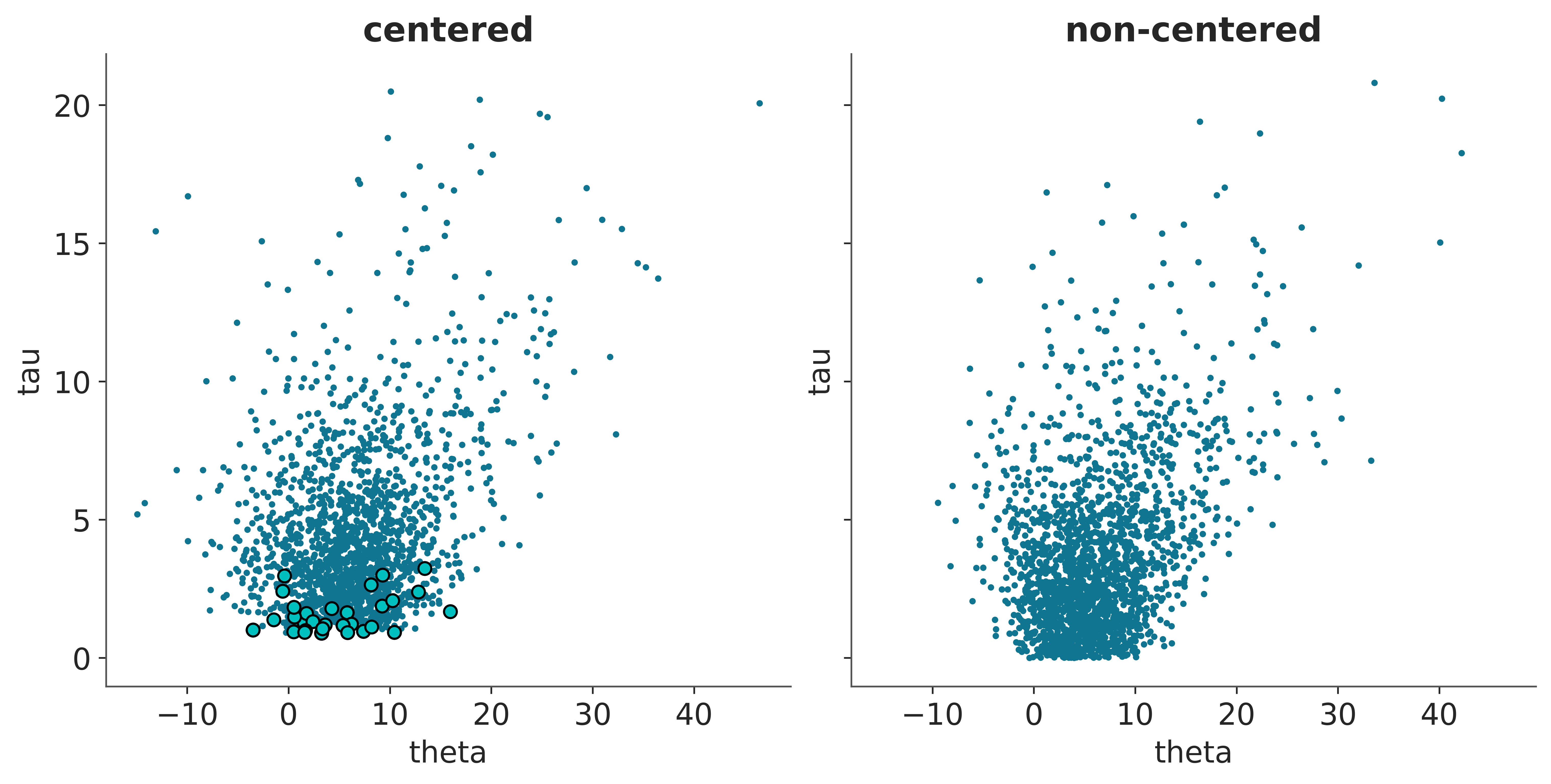
4.6 What to do when the diagnoses are wrong?
More samples or more tuning steps. This is usually only useful when the problems are minor
Burn-in. Modern software like PyMC uses several samples to tune the hyper-parameters of the sampling methods. By default, these samples are eliminated, so in general, it is not necessary to do Burn-in manually.
Change sampling method!
Reparameterize the model
Improve priors
- The folk theorem of computational statistics: When you have computational problems, there is often a problem with your model. The recommendation is NOT to change the priors to improve sampling quality. The recommendation is that if the sampling is bad, perhaps the model is too. In that case, we can think about improving the model, one way to improve it is to use prior knowledge to improve the priors.
Some models can be expressed in more than one way, all mathematically equivalent. In those cases, some parameterizations may be more efficient than others. For example, as we will see later with hierarchical linear models.
In the case of divergences, these are usually eliminated by increasing the acceptance rate, for instance in PyMC you can do
pm.sample(..., target_accept=x)wherexis 0.8 by default and the maximum value is 1. If you reach 0.99 you should probably do something else.Modern probabilistic programming languages, usually provide useful warning messages and tips if they detect issues with sampling, paying attention to those messages can save you a lot of time.