ArviZ.jl Quickstart
This quickstart is adapted from ArviZ's Quickstart.
using ArviZ
# ArviZ ships with style sheets!
ArviZ.use_style("arviz-darkgrid")Get started with plotting
ArviZ.jl is designed to be used with libraries like CmdStan, Turing.jl, and Soss.jl but works fine with raw arrays.
using Random
rng = Random.MersenneTwister(42)
plot_posterior(randn(rng, 100_000));
Plotting a dictionary of arrays, ArviZ.jl will interpret each key as the name of a different random variable. Each row of an array is treated as an independent series of draws from the variable, called a chain. Below, we have 10 chains of 50 draws each for four different distributions.
using Distributions
s = (10, 50)
plot_forest(Dict(
"normal" => randn(rng, s),
"gumbel" => rand(rng, Gumbel(), s),
"student t" => rand(rng, TDist(6), s),
"exponential" => rand(rng, Exponential(), s)
));
Plotting with MCMCChains.jl's Chains objects produced by Turing.jl
ArviZ is designed to work well with high dimensional, labelled data. Consider the eight schools model, which roughly tries to measure the effectiveness of SAT classes at eight different schools. To show off ArviZ's labelling, I give the schools the names of a different eight schools.
This model is small enough to write down, is hierarchical, and uses labelling. Additionally, a centered parameterization causes divergences (which are interesting for illustration).
First we create our data and set some sampling parameters.
J = 8
y = [28.0, 8.0, -3.0, 7.0, -1.0, 1.0, 18.0, 12.0]
σ = [15.0, 10.0, 16.0, 11.0, 9.0, 11.0, 10.0, 18.0]
schools = [
"Choate",
"Deerfield",
"Phillips Andover",
"Phillips Exeter",
"Hotchkiss",
"Lawrenceville",
"St. Paul's",
"Mt. Hermon"
];
nwarmup, nsamples, nchains = 1000, 1000, 4;Now we write and run the model using Turing:
using Turing
Turing.@model turing_model(
J,
y,
σ,
::Type{TV} = Vector{Float64},
) where {TV} = begin
μ ~ Normal(0, 5)
τ ~ truncated(Cauchy(0, 5), 0, Inf)
θ = TV(undef, J)
θ .~ Normal(μ, τ)
y ~ MvNormal(θ, σ)
end
param_mod = turing_model(J, y, σ)
sampler = NUTS(nwarmup, 0.8)
rng = Random.MersenneTwister(5130)
turing_chns = psample(
param_mod,
sampler,
nwarmup + nsamples,
nchains;
progress = false,
);Most ArviZ functions work fine with Chains objects from Turing:
plot_autocorr(turing_chns; var_names = ["μ", "τ"]);
Convert to InferenceData
For much more powerful querying, analysis and plotting, we can use built-in ArviZ utilities to convert Chains objects to xarray datasets. Note we are also giving some information about labelling.
ArviZ is built to work with InferenceData (a netcdf datastore that loads data into xarray datasets), and the more groups it has access to, the more powerful analyses it can perform.
idata = from_mcmcchains(
turing_chns,
coords = Dict("school" => schools),
dims = Dict(
"y" => ["school"],
"σ" => ["school"],
"θ" => ["school"],
),
library = "Turing",
)InferenceData with groups:
> posterior
> sample_statsEach group is an ArviZ.Dataset (a thinly wrapped xarray.Dataset). We can view a summary of the dataset.
idata.posterior- chain: 4
- draw: 1000
- school: 8
- chain(chain)int640 1 2 3
array([0, 1, 2, 3])
- draw(draw)int640 1 2 3 4 5 ... 995 996 997 998 999
array([ 0, 1, 2, ..., 997, 998, 999])
- school(school)<U16'Choate' ... 'Mt. Hermon'
array(['Choate', 'Deerfield', 'Phillips Andover', 'Phillips Exeter', 'Hotchkiss', 'Lawrenceville', "St. Paul's", 'Mt. Hermon'], dtype='<U16')
- μ(chain, draw)float641.235 4.837 8.871 ... 6.926 0.9602
array([[ 1.23534347e+00, 4.83678742e+00, 8.87127701e+00, ..., -2.79310378e+00, -3.27726470e+00, -1.76322873e+00], [ 1.13335463e+00, 1.54834388e+00, 1.68058084e+00, ..., 1.29536794e+00, 9.46791803e-01, 7.84587219e-01], [ 2.09525182e+00, -1.88269404e-01, 9.81208721e+00, ..., 7.49499435e+00, 1.38047841e-01, -4.28512263e-03], [-2.20533718e+00, 3.94853472e+00, 2.79237924e+00, ..., 4.48138709e+00, 6.92588162e+00, 9.60205729e-01]]) - τ(chain, draw)float6413.2 7.413 6.789 ... 1.474 2.12
array([[13.20124552, 7.41258164, 6.78856079, ..., 6.75954136, 5.8842155 , 6.03597309], [ 1.2734498 , 1.33177867, 1.21255003, ..., 2.82095408, 4.48768288, 5.70074035], [ 4.82307376, 7.52038035, 8.87661558, ..., 2.48285217, 3.15393432, 3.73209175], [ 5.91041402, 5.18278378, 9.22462862, ..., 2.32076345, 1.47425491, 2.12019324]]) - θ(chain, draw, school)float6414.53 -2.974 ... 3.224 0.02335
array([[[ 1.45348093e+01, -2.97444321e+00, -1.11054859e+01, ..., -3.86458329e+00, 2.01818654e+01, 1.95490039e+01], [ 3.90178776e+00, -9.46207065e+00, -1.53415329e+01, ..., 3.49222455e+00, 1.77158806e+01, 3.28078623e+00], [ 1.08688132e+01, 8.96784312e+00, 1.72342453e+01, ..., 2.39865398e-01, 4.07615836e-01, 5.15628505e+00], ..., [ 1.78757221e+00, -2.85918258e+00, -1.37106411e+01, ..., 1.51133365e+00, -2.20044255e+00, -8.54988902e+00], [-4.13154080e+00, 3.81585504e+00, -1.09468445e+01, ..., 5.55087803e+00, 3.84067634e+00, -6.36864284e+00], [-3.34387524e+00, 2.37678821e+00, -1.27918132e+01, ..., 5.04158084e+00, 3.16702887e+00, 7.23273726e-01]], [[ 1.13625997e+00, 7.77876956e-01, 9.25127841e-01, ..., 4.97492315e-01, 7.16312793e-02, 8.28478324e-01], [ 2.31449947e+00, 7.48708554e-01, 1.79386545e+00, ..., 9.32254221e-01, 1.51800309e+00, 1.69552472e+00], [ 1.02027306e+00, 2.49448557e+00, 1.27215777e+00, ..., 1.34979830e+00, 2.09887747e+00, 1.22076861e+00], ..., [ 2.88578317e+00, -3.43755050e+00, 4.84768886e+00, ..., 3.04386737e+00, 3.78735553e+00, 1.68380670e+00], [-2.73251886e-01, -1.23241481e+00, 5.48086965e+00, ..., 2.82469556e+00, 3.52009922e+00, 2.59313474e+00], [ 5.01173285e+00, 4.86981121e+00, -3.20948093e+00, ..., 1.27993807e+00, 5.58776441e+00, -4.05322805e+00]], [[ 6.38541268e+00, 7.93857879e+00, -4.66201354e+00, ..., -6.24825330e-01, 8.08212190e+00, 2.31497186e-01], [ 3.40350867e+00, -5.88691926e+00, 2.47379392e+00, ..., 5.81096727e+00, -2.20684830e+00, -1.30100458e+01], [ 2.46441945e+01, 1.25791669e+01, -3.97257734e-01, ..., -1.04168791e+01, 2.03620424e+01, 2.38216433e+01], ..., [ 1.05184969e+01, 6.87397886e+00, 1.20252235e+01, ..., 7.45104586e+00, 6.27692985e+00, 6.36510734e+00], [ 4.26747924e+00, -3.43873771e-01, 3.90888316e+00, ..., 1.68758244e-01, -9.23834746e-01, 2.79277535e+00], [ 4.77724511e-01, 4.45743258e+00, 2.88554297e+00, ..., -4.29705229e-01, 5.41238871e-01, 7.54621399e-01]], [[ 7.98345542e+00, -2.85986332e+00, -2.59106903e+00, ..., -1.11511568e+01, 1.64472538e+00, 6.74064163e+00], [-2.03509543e+00, 1.01301275e+01, 1.83056669e+00, ..., 5.15417192e+00, 7.05046454e+00, 4.57066862e+00], [ 1.44630255e+01, -2.90562147e-02, -4.30510032e+00, ..., 6.06787113e-01, 3.26072076e+00, -5.10606040e+00], ..., [ 4.44810258e+00, 1.33478476e+00, 2.00091201e+00, ..., 3.44200955e-01, 4.31265715e+00, 7.24614879e+00], [ 7.39221975e+00, 7.15056434e+00, 7.21958722e+00, ..., 9.46262410e+00, 5.91568190e+00, 5.02864574e+00], [ 1.71488979e-01, -1.49344629e+00, 3.52902685e-01, ..., -4.71335503e-01, 3.22386352e+00, 2.33483443e-02]]])
- created_at :
- 2020-02-27T06:32:12.330412
- inference_library :
- Turing
Here is a plot of the trace. Note the intelligent labels.
plot_trace(idata);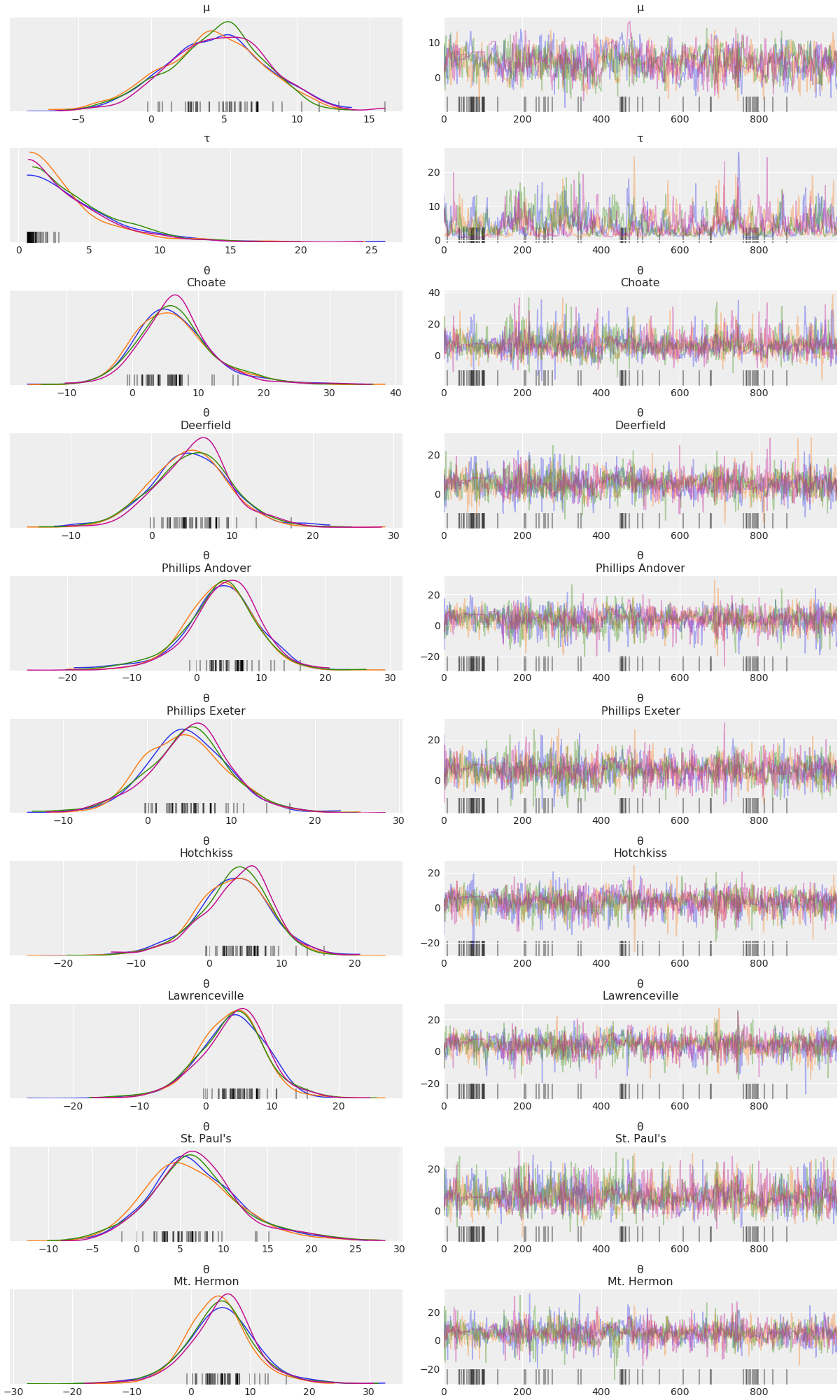
We can also generate summary stats
summarystats(idata)| mean | sd | hpd_3% | hpd_97% | mcse_mean | mcse_sd | ess_mean | ess_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| μ | 4.437 | 3.455 | -1.905 | 10.928 | 0.161 | 0.114 | 458.0 | 458.0 | 461.0 | 1041.0 | 1.01 |
| τ | 4.243 | 3.207 | 0.691 | 10.049 | 0.182 | 0.128 | 312.0 | 312.0 | 172.0 | 89.0 | 1.05 |
| θ[1] | 6.632 | 6.050 | -4.646 | 18.228 | 0.201 | 0.142 | 908.0 | 908.0 | 791.0 | 1424.0 | 1.01 |
| θ[2] | 5.075 | 4.954 | -4.171 | 14.577 | 0.159 | 0.113 | 967.0 | 967.0 | 866.0 | 1884.0 | 1.01 |
| θ[3] | 3.805 | 5.652 | -6.956 | 14.573 | 0.166 | 0.117 | 1162.0 | 1162.0 | 1056.0 | 1743.0 | 1.01 |
| θ[4] | 4.883 | 4.987 | -4.407 | 14.330 | 0.151 | 0.107 | 1089.0 | 1089.0 | 1036.0 | 1750.0 | 1.01 |
| θ[5] | 3.423 | 5.071 | -7.170 | 12.195 | 0.155 | 0.110 | 1070.0 | 1070.0 | 951.0 | 1671.0 | 1.01 |
| θ[6] | 3.952 | 5.122 | -5.700 | 13.803 | 0.160 | 0.113 | 1024.0 | 1024.0 | 936.0 | 1627.0 | 1.00 |
| θ[7] | 6.794 | 5.288 | -2.808 | 17.764 | 0.191 | 0.135 | 765.0 | 765.0 | 730.0 | 1668.0 | 1.01 |
| θ[8] | 4.978 | 5.685 | -5.908 | 16.139 | 0.161 | 0.119 | 1246.0 | 1143.0 | 1069.0 | 1892.0 | 1.01 |
and examine the energy distribution of the Hamiltonian sampler
plot_energy(idata);
Plotting with CmdStan.jl outputs
CmdStan.jl and StanSample.jl also default to producing Chains outputs, and we can easily plot these chains.
Here is the same centered eight schools model:
using CmdStan, MCMCChains
schools_code = """
data {
int<lower=0> J;
real y[J];
real<lower=0> sigma[J];
}
parameters {
real mu;
real<lower=0> tau;
real theta[J];
}
model {
mu ~ normal(0, 5);
tau ~ cauchy(0, 5);
theta ~ normal(mu, tau);
y ~ normal(theta, sigma);
}
generated quantities {
vector[J] log_lik;
vector[J] y_hat;
for (j in 1:J) {
log_lik[j] = normal_lpdf(y[j] | theta[j], sigma[j]);
y_hat[j] = normal_rng(theta[j], sigma[j]);
}
}
"""
schools_dat = Dict("J" => J, "y" => y, "sigma" => σ)
stan_model = Stanmodel(
model = schools_code,
name = "schools",
nchains = nchains,
num_warmup = nwarmup,
num_samples = nsamples,
output_format = :mcmcchains,
random = CmdStan.Random(8675309),
)
_, stan_chns, _ = stan(stan_model, schools_dat, summary = false);
File /home/vsts/work/1/s/docs/build/tmp/schools.stan will be updated.plot_density(stan_chns; var_names=["mu", "tau"]);
Again, converting to InferenceData, we can get much richer labelling and mixing of data. Note that we're using the same from_cmdstan function used by ArviZ to process cmdstan output files, but through the power of dispatch in Julia, if we pass a Chains object, it instead uses ArviZ.jl's overloads, which forward to from_mcmcchains.
idata = from_cmdstan(
stan_chns;
posterior_predictive = "y_hat",
observed_data = Dict("y" => schools_dat["y"]),
log_likelihood = "log_lik",
coords = Dict("school" => schools),
dims = Dict(
"y" => ["school"],
"sigma" => ["school"],
"theta" => ["school"],
"log_lik" => ["school"],
"y_hat" => ["school"],
),
)InferenceData with groups:
> posterior
> posterior_predictive
> sample_stats
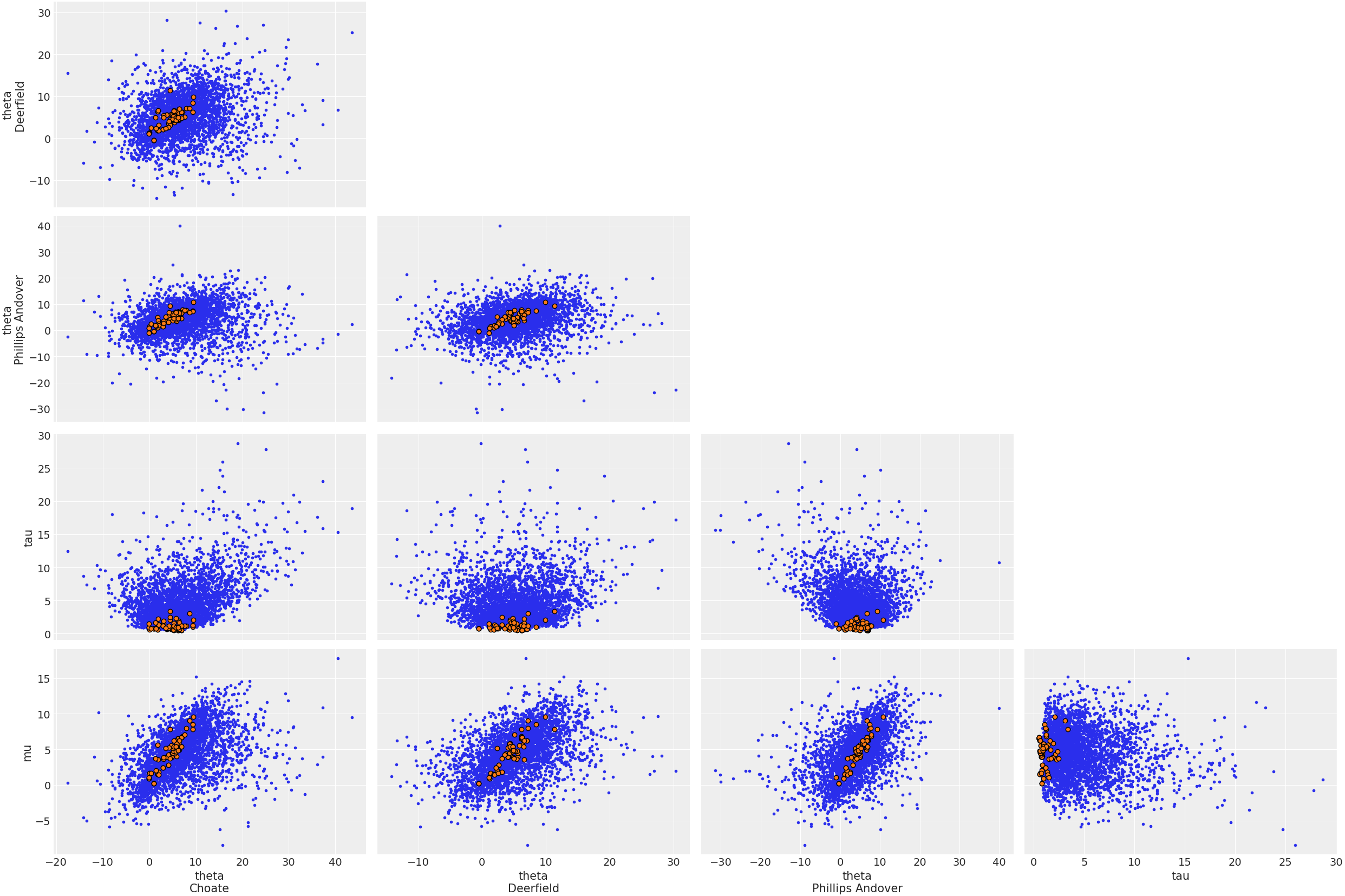
> observed_dataHere is a plot showing where the Hamiltonian sampler had divergences:
plot_pair(
idata;
coords = Dict("school" => ["Choate", "Deerfield", "Phillips Andover"]),
divergences = true,
);
Plotting with Soss.jl outputs
With Soss, we can define our model for the posterior and easily use it to draw samples from the prior, prior predictive, posterior, and posterior predictive distributions.
First we define our model:
using Soss, NamedTupleTools
mod = Soss.@model (J, σ) begin
μ ~ Normal(0, 5)
τ ~ HalfCauchy(5)
θ ~ Normal(μ, τ) |> iid(J)
y ~ For(1:J) do j
Normal(θ[j], σ[j])
end
end
constant_data = (J = J, σ = σ)
param_mod = mod(; constant_data...)Joint Distribution
Bound arguments: [J, σ]
Variables: [τ, μ, θ, y]
@model (J, σ) begin
τ ~ HalfCauchy(5)
μ ~ Normal(0, 5)
θ ~ Normal(μ, τ) |> iid(J)
y ~ For(1:J) do j
Normal(θ[j], σ[j])
end
end
Then we draw from the prior and prior predictive distributions.
Random.seed!(5298)
prior_prior_pred = map(1:nchains*nsamples) do _
draw = rand(param_mod)
return delete(draw, keys(constant_data))
end
prior = map(draw -> delete(draw, :y), prior_prior_pred)
prior_pred = map(draw -> delete(draw, (:μ, :τ, :θ)), prior_prior_pred);Next, we draw from the posterior using DynamicHMC.jl.
post = map(1:nchains) do _
dynamicHMC(param_mod, (y = y,), nsamples)
end;Finally, we use the posterior samples to draw from the posterior predictive distribution.
pred = predictive(mod, :μ, :τ, :θ)
post_pred = map(post) do post_draws
map(post_draws) do post_draw
pred_draw = rand(pred(post_draw)(constant_data))
return delete(pred_draw, keys(constant_data))
end
end;Each Soss draw is a NamedTuple. We can plot the rank order statistics of the posterior to identify poor convergence:
plot_rank(post; var_names = ["μ", "τ"]);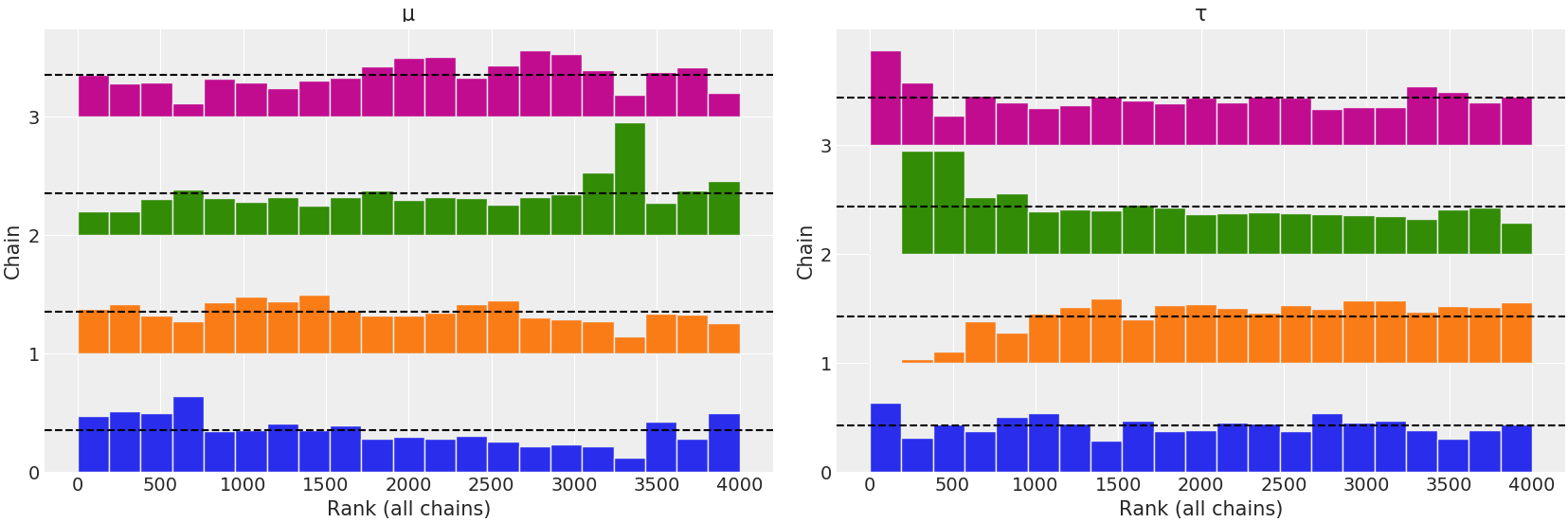
Now we combine all of the samples to an InferenceData:
idata = from_namedtuple(
post;
posterior_predictive = post_pred,
prior = [prior],
prior_predictive = [prior_pred],
observed_data = Dict("y" => y),
constant_data = constant_data,
coords = Dict("school" => schools),
dims = Dict(
"y" => ["school"],
"σ" => ["school"],
"θ" => ["school"],
),
library = Soss,
)InferenceData with groups:
> posterior
> posterior_predictive
> prior
> prior_predictive
> observed_data
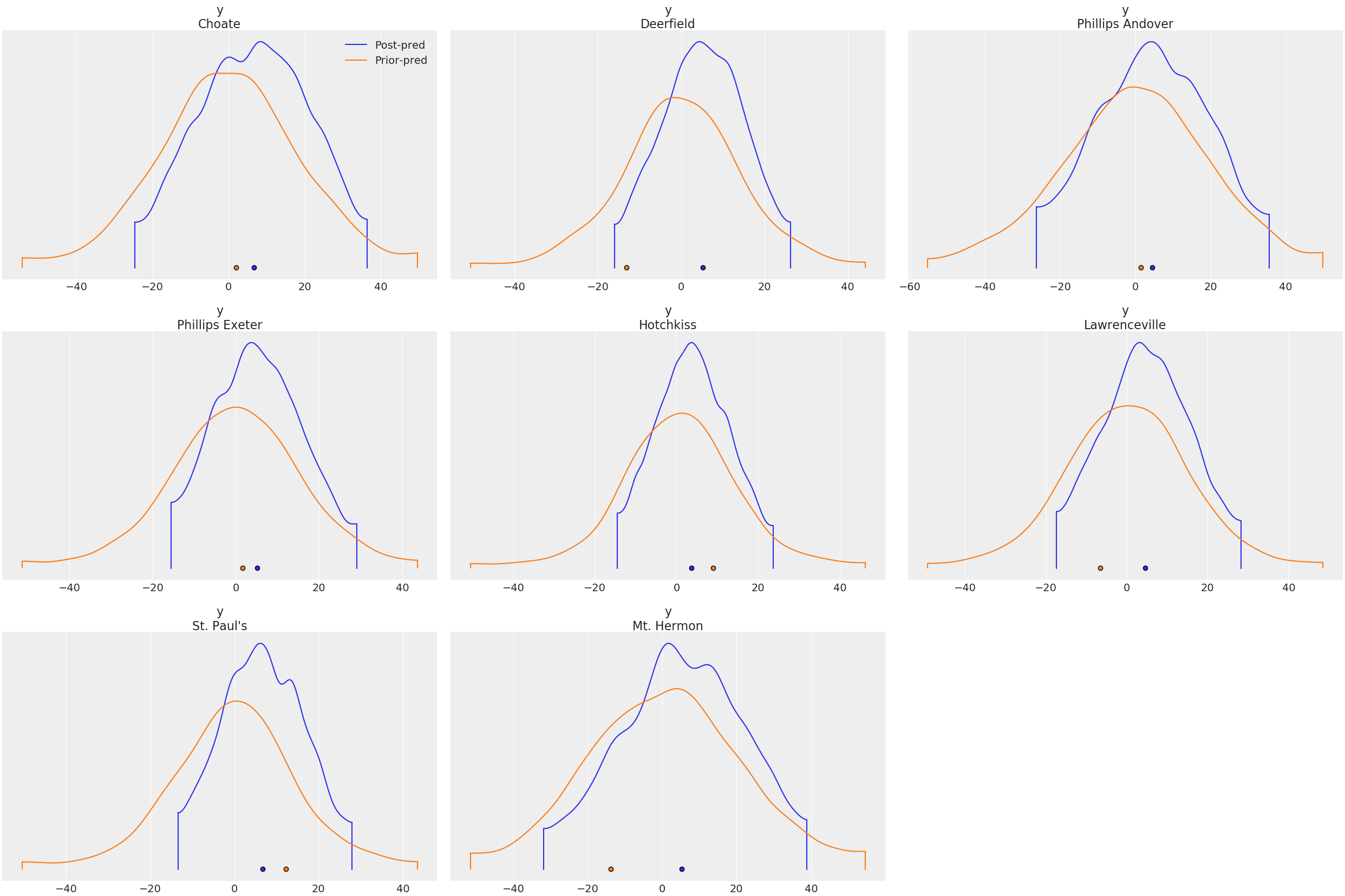
> constant_dataWe can compare the prior and posterior predictive distributions:
plot_density(
[idata.posterior_predictive, idata.prior_predictive];
data_labels = ["Post-pred", "Prior-pred"],
var_names = ["y"],
)
Environment
using Pkg
Pkg.status() Status `~/work/1/s/docs/Project.toml`
[131c737c] ArviZ v0.3.3 [`~/work/1/s`]
[593b3428] CmdStan v6.0.2
[31c24e10] Distributions v0.22.4
[e30172f5] Documenter v0.24.5
[c7f686f2] MCMCChains v3.0.0
[d9ec5142] NamedTupleTools v0.12.1
[8ce77f84] Soss v0.10.0 #master (https://github.com/cscherrer/Soss.jl.git)using InteractiveUtils
versioninfo()Julia Version 1.3.1
Commit 2d5741174c (2019-12-30 21:36 UTC)
Platform Info:
OS: Linux (x86_64-pc-linux-gnu)
CPU: Intel(R) Xeon(R) CPU E5-2673 v4 @ 2.30GHz
WORD_SIZE: 64
LIBM: libopenlibm
LLVM: libLLVM-6.0.1 (ORCJIT, broadwell)
Environment:
JULIA_VERSION = 1.3
JULIA_CMDSTAN_HOME = /home/vsts/work/_temp/.cmdstan//cmdstan-2.22.1/